PostgreSQL Indexing Types: How & When to Use Them
Author: Shailesh Rangani | | July 15, 2020
PostgreSQL is one of the most advanced leading open-source relational databases and it comes with very rich features, functionalities, and wide varieties of extensions. PostgreSQL provides a variety of index types. There are often questions on what type of index performs best and answer is: “It depends on the use case.”
In this article, let’s look at what are indexes supported by PostgreSQL following with when to use which type of index.
B-Tree
- Default index type.
- Best fit for most of the queries.
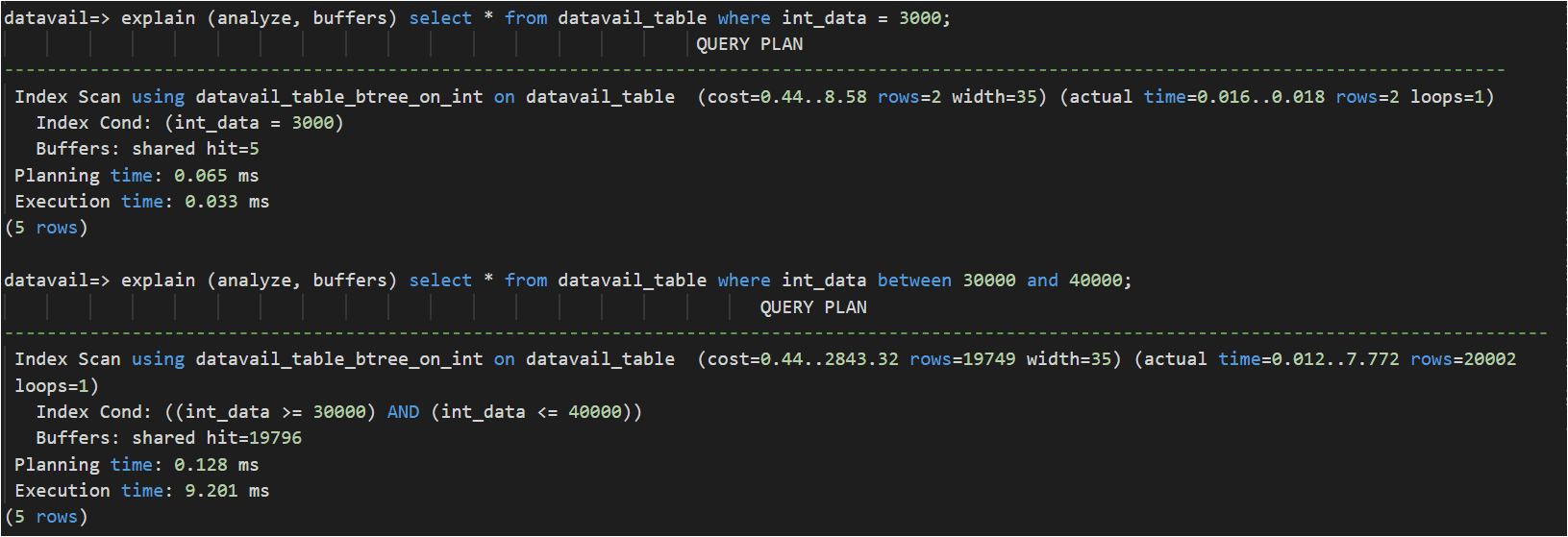
- Good fit for operations like >, >=, <, <=, =, IN, BETWEEN etc.
- Supports multi-columns.
PostgreSQL 13 is expected to have enhancements that will have a way to handle duplicate data efficiently, this will help in reducing B-Tree index size significantly.
From below execution plan: = , IN, BETWEEN cases, optimizer uses B-Tree index.
Hash
Before PostgreSQL version 10, hash index operations were not WAL-logged, so REINDEXing is needed after a database crash. For this reason, hash index use was discouraged for previous versions. However, if you are using PostgreSQL 10 or older hash index is crash-safe.
- Hash index can be created using the “USING HASH” keyword.
- Good fit for equality operations.
- Does not support the multi-columns index.
- Index size is small compare to the B-tree index hence occupy less space.
- Because of smaller in size, it fits in memory and reads less from disk or even shared_buffers, hence improves performance.
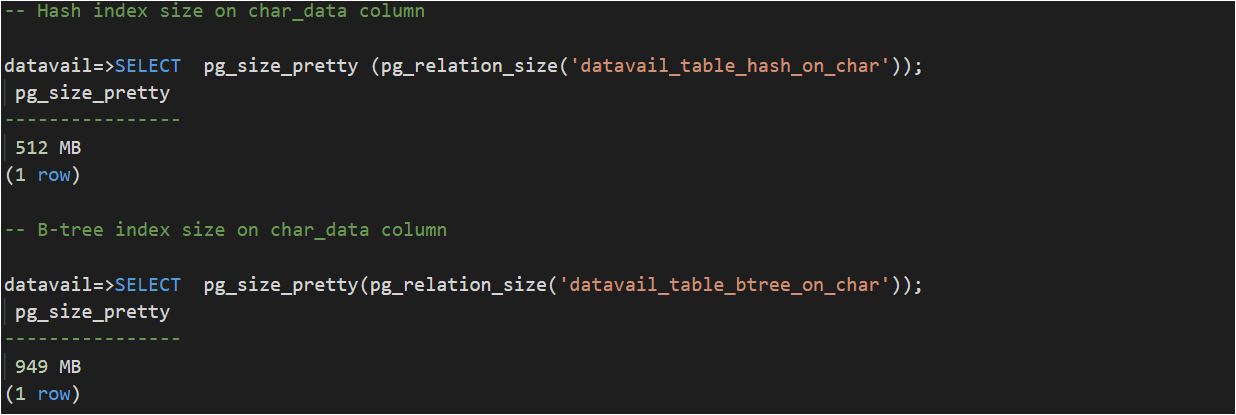
In the test performed against a sample table of 20 million records, the size of the hash index (datatype character varying (30)) is almost half of the B-tree index.

B-tree Vs Hash Index size:
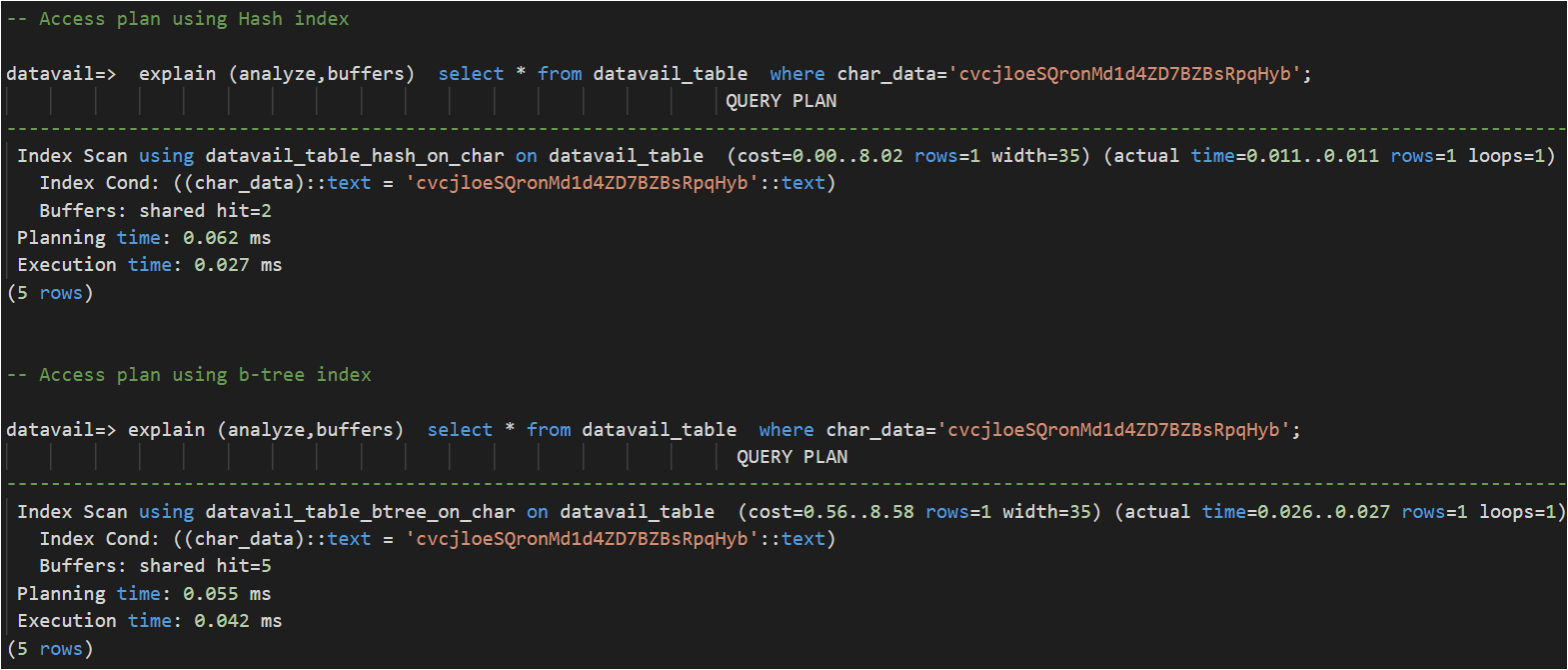
In a test performed below, the Hash index pulls 2 blocks vs 5 blocks from the memory of B-tree.
BRIN (Block Range Indexes: 9.5 and above)
Sensors, devices, tracking-based applications have one common characteristic: “A timestamp that is always increasing.” PostgreSQL 9.5 introduced a new type of index called BRIN to improve the performance of such use cases.
- Good fit for time-series data or data which has liner sort order.
- Stores the page’s minimum value and maximum value of indexed column.
- Performs better than B-Tree for liner data use cases.
- Very small in size compare to B-Tree
- Lossy in nature (as workaround: it performs little revalidation work and discard any tuples which don’t satisfy the condition)
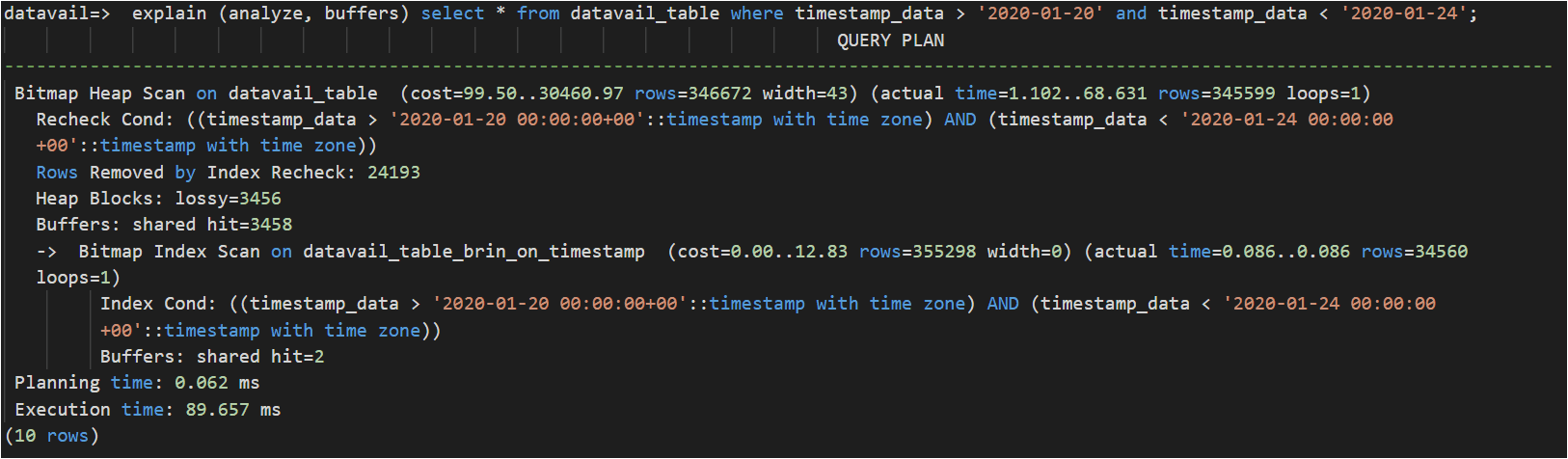
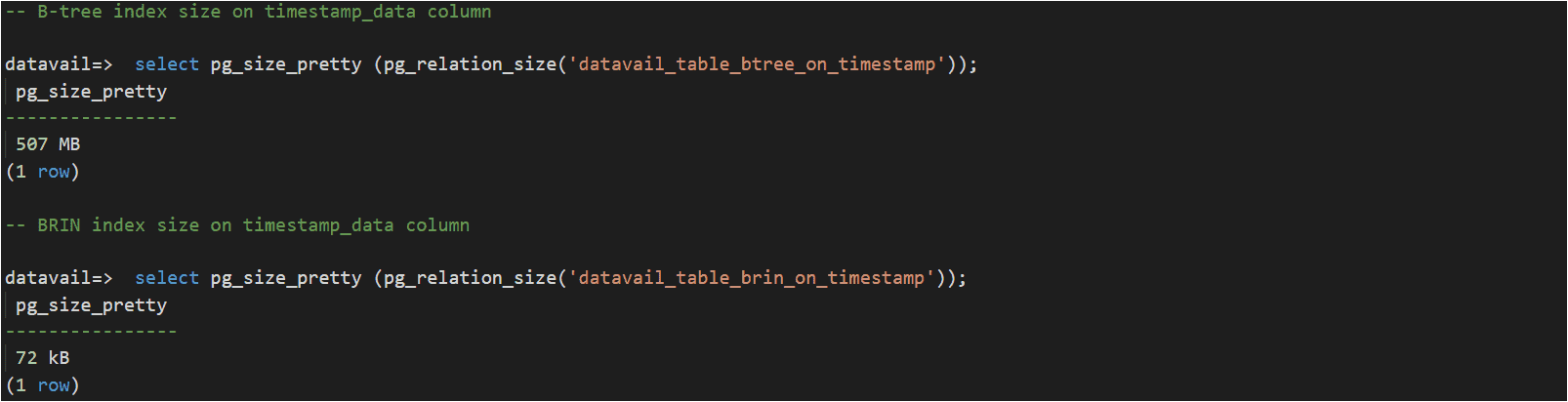
In the below test (timestamp_data column is time series data) with 20 million records in the table, the BRIN index outperformed ~10% better than B-tree while also saving 99% of storage space compared to B-tree.
Using the B-Tree Index:

Using the BRIN Index:
B-tree Vs BRIN Index size:
Generalized Inverted Index (GIN)
- GIN is also called inverted index.
- Good fit for JSONB data, Array, Range Types, Full text search and hStore.
- Individual element gets indexed instead of entire value for indexed column.
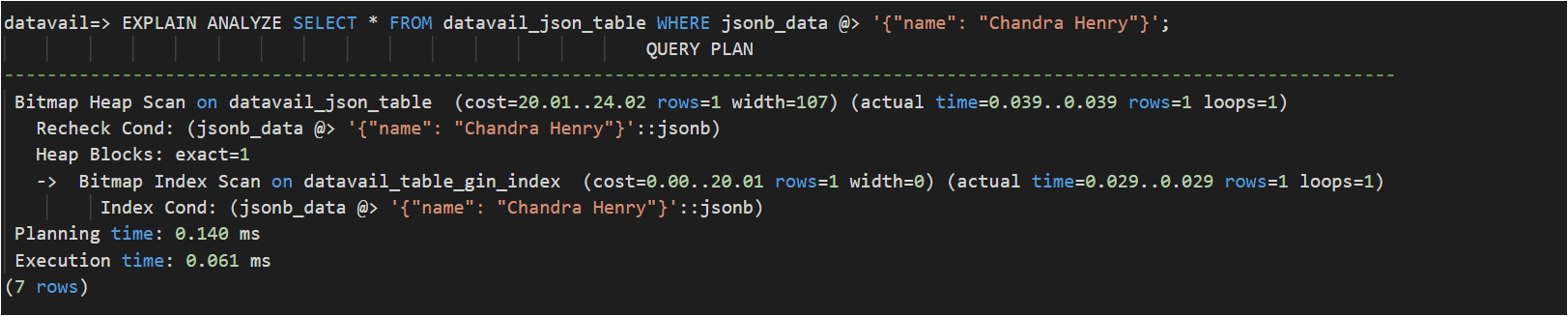
The below use case describes the significance of the GIN index on the JSONB data type and its performance impact.
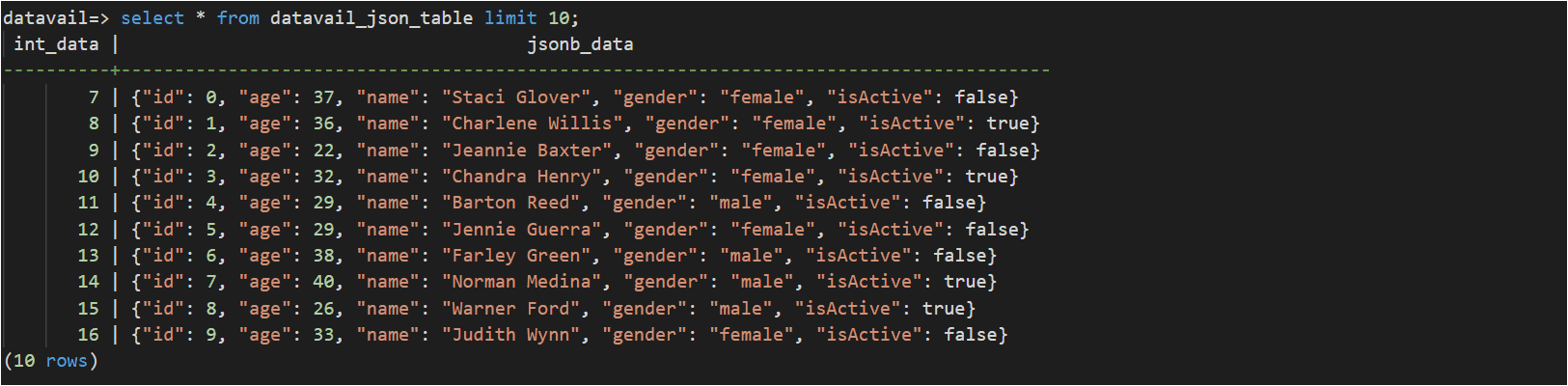
Sequential scan before index:

GIN Index:

Faster data access after index creation:
Generalized Inverted Search Tree (GiST)
- GiST is a balanced tree-like B-tree.
- Good fit for Full-text search or Geometric types.
- For dynamic data, GiST is a better option compare to GIN.
A less known fact: The size of maintenance_work_mem doesn’t impact the performance of the GiST index unlike GIN or other indexes.
Partial Index
- Index with “where” cause.
- Good fit if you want to index only subset of tables’ data.
- Segment of records are indexed, so it is small and efficient.
- Use case: selecting hotel names whose ratings are 3 or more. In this use case, there is no point in creating an index for all records whose ratings are < 3.
In below example, created a partial index for records less than 2000.

For index column criteria fitting in partial index range (i.e. < 2000), the optimizer uses a partial index.

If index column criteria don’t fit in partial index range (i.e. >= 2000), a partial index doesn’t get used.
Expression Index
- Good fit if query has function or expression on indexed column. (i.e. (lower(column_name)).
- Outcome of the function or expression gets indexed, not the original column data.
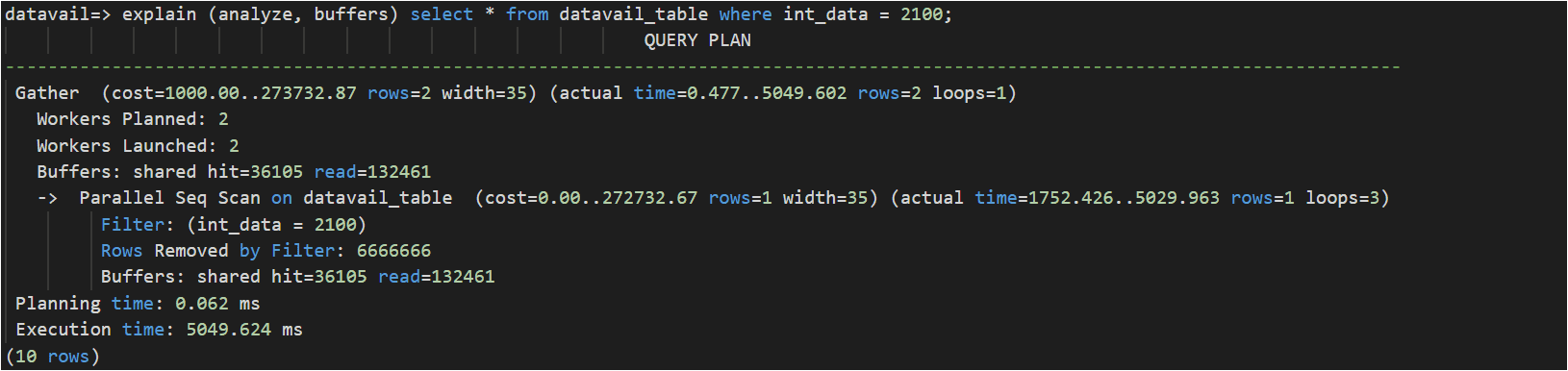
In the below use case, we want to find all records where the date is 5th. Even there is a B-tree index on the timestamp_data column it will not be used since there is a function applied while querying these records.
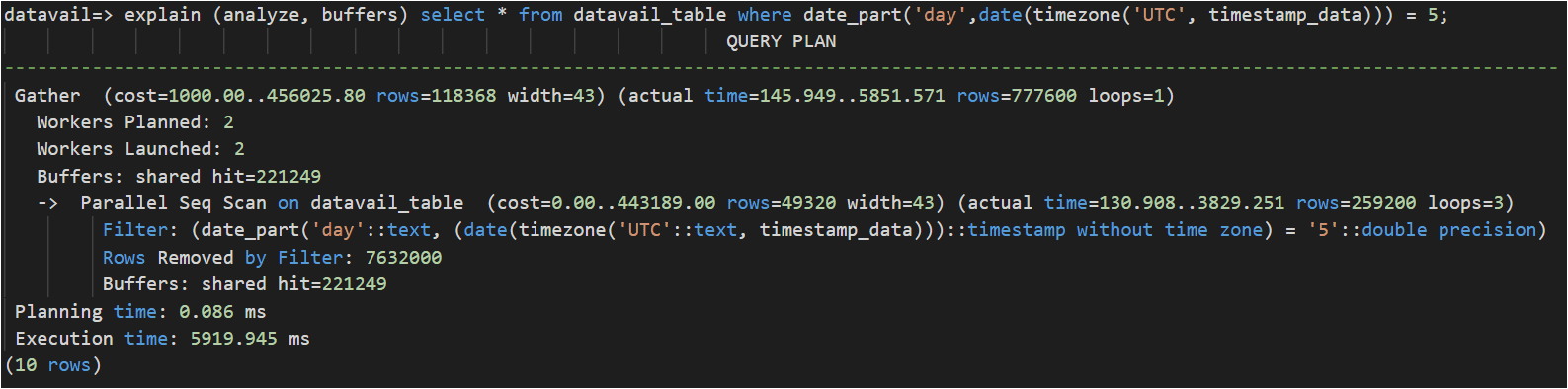
To improve performance, created expression/function index:

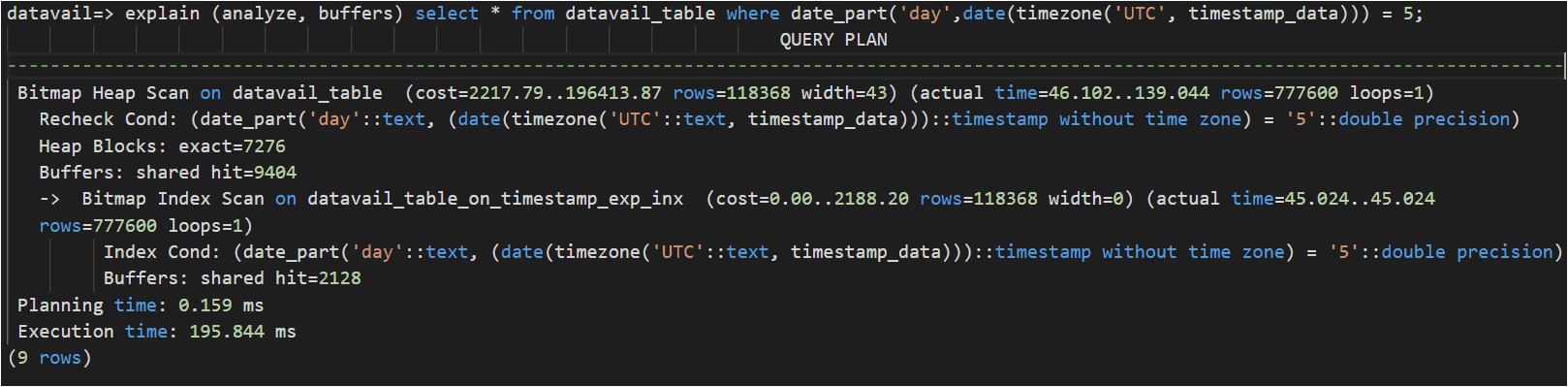
Comparison:
| Index Type: | B-Tree | Hash | BRIN | GIN | GiST |
| Use Cases: | # Most of use cases.
# =, >=, <=, >, <, IN, BETWEEN operations |
# Equality (=) operations. # High cardinality column as an indexed column |
# Timestamped sensor data. # Internet of Things (IoT) # Sequentially lined up large data set |
# Static data # Index arrays, jsonb, and tsvector# Full text search (LIKE ‘%string%’) # Efficient for <@, &&, @@@ operators |
# Dynamic data # Geometries, array # Useful when using PostGIS # Full text search (LIKE ‘%string%’) |
| Index Size: | Large compare to Hash and BRIN | Small compare to B-Tree | Very small in size | Large compare to GiST | Small compare to GIN |
Indexes are quite useful for speeding up database queries. PostgreSQL comes with a variety of index types that use distinct algorithms to speed up different queries. However, each index is a write penalty and can slow down INSERT, UPDATE, and DELETE. Which type of index to use is purely depends on the data type, underlying data within the table and types of lookups performed. If you are looking for PostgreSQL support, please reach out to our experts.
Read These Next:
White Paper: Going Open-Source: Why and How to Migrate from Oracle to PostgreSQL
Service Overview: PostgreSQL Services
White Paper: Don’t Let Oracle High Availability Features Stop You From Migrating to PostgreSQL

Blog Author
Related Posts

How to Solve the Oracle Error ORA-12154: TNS:could not resolve the connect identifier specified
The “ORA-12154: TNS Oracle error message is very common for database administrators. Learn how to diagnose & resolve this common issue here today.

Data Types: The Importance of Choosing the Correct Data Type
Most DBAs have struggled with the pros and cons of choosing one data type over another. This blog post discusses different situations.

How to Recover a Table from an Oracle 12c RMAN Backup
Our database experts explain how to recover and restore a table from an Oracle 12c RMAN Backup with this step-by-step blog. Read more.