SQL Server In-Memory OLTP – New Index – Hash Index
Author: Pinal Dave | 4 min read | March 27, 2015
If we ask any DBA about the types of indexes in SQL Server, most likely they would answer – clustered index and non-clustered index. This is no longer valid from SQL Server 2014 onwards, in which Microsoft introduced new types of tables called in-memory tables. The storage of these tables is not a traditional MDF file where data is stored in 8 KB pages. Traditional indexes are also no longer valid for these in-memory tables. There are two new indexes that can be created only on in-memory tables – called hash index and range index.
Before we explain hash index, let’s first cover what “hashing” is. For the sake of simplicity, assume that a hash function is a function which would take the value as an input parameter and provided a “hash” key as an output. For illustration purposes, assume the hash function is length – which gives length of the input string as output. If we pass “SQL” as input, our sample hash function (len) is going to give us 3 as output. If we pass “Hekaton” as input, the output would be 7. If we have an index with 10 buckets, “SQL” would fall into bucket # 3 and “Hekaton” would fall into bucket # 7. In reality, the function is much more complex than length, but that is for another blog.
The hash index is a list of pointers and each of them is called a bucket. Hash index is defined as “non-clustered hash” index during table creation. We don’t have an option to add an index once the table is created. All indexes must be defined during the table creation itself. It has a predefined number of buckets. These indexes are useful and beneficial for lookups in our query.
To see this in action, let’s create a database and a table with a hash index. You can run the script below in SQL Server 2014. Make changes as per your environment (you can create InMemoryDatabase folder on C Drive to run as-is):
IF EXISTS (
SELECT *
FROM sys.databases
WHERE name = N'InMemoryDatabase'
)
DROP DATABASE InMemoryDatabase
GO
CREATE DATABASE InMemoryDatabase
ON PRIMARY
(NAME = InMemoryDatabase_MDF,
FILENAME = N'C:InMemoryDatabaseInMemoryDatabase.mdf'),
FILEGROUP InMemoryDatabase_IMO CONTAINS MEMORY_OPTIMIZED_DATA
( NAME = InMemoryDatabase_IMO,
FILENAME = N'C:InMemoryDatabaseInMemoryDatabase_FG')
LOG ON
( NAME = InMemoryDatabase_LDF,
FILENAME = N'C:InMemoryDatabaseInMemoryDatabase.ldf')
COLLATE Latin1_General_100_BIN2
GO
Once the database is created, we are creating table InMemoryTable
USE InMemoryDatabase
GO
CREATE TABLE InMemoryTable (
ID BIGINT NOT NULL,
NAME VARCHAR(10) NOT NULL,
PRIMARY KEY NONCLUSTERED HASH (NAME) WITH ( BUCKET_COUNT = 16 )
) WITH ( MEMORY_OPTIMIZED=ON,
DURABILITY=SCHEMA_AND_DATA );
Notice that what we have created has index on NAME column with 16 buckets. If we insert 4 rows, here is how they will get organized:
set nocount on go insert into InMemoryTable values (1, 'Hekaton'); insert into InMemoryTable values (2, 'Microsoft'); insert into InMemoryTable values (3, 'SQL'); insert into InMemoryTable values (4, 'Collision'); go
Here is how the index would be laid out.
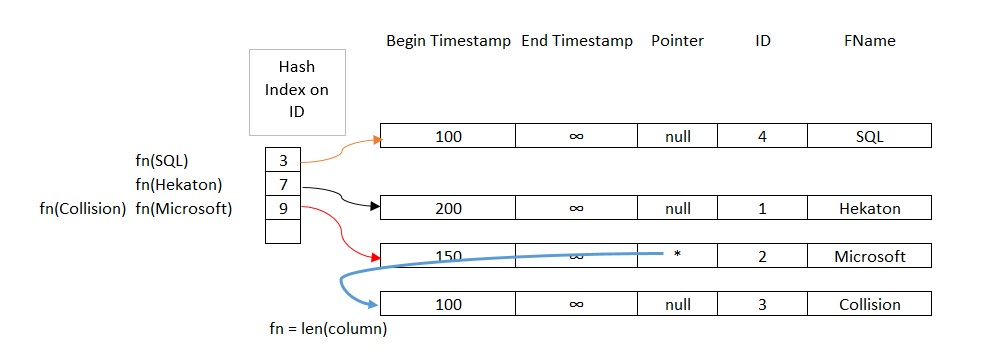
To understand the row structure, there are many resources online. Pointer is basically a pointer to the next row if there is a collision. In our example, Microsoft and Collision has same length (9), so the hash index would point to the first row. This can be confirmed by the query below as well:
SELECT Object_name(his.object_id) 'Table Name',
idx.name 'Index Name',
total_bucket_count 'total buckets',
empty_bucket_count 'empty buckets',
total_bucket_count - empty_bucket_count as 'used buckets',
avg_chain_length 'avg chain length',
max_chain_length 'max chain length'
FROM sys.dm_db_xtp_hash_index_stats as his
JOIN sys.indexes as idx
ON his.object_id = idx.object_id
AND his.index_id = idx.index_id;
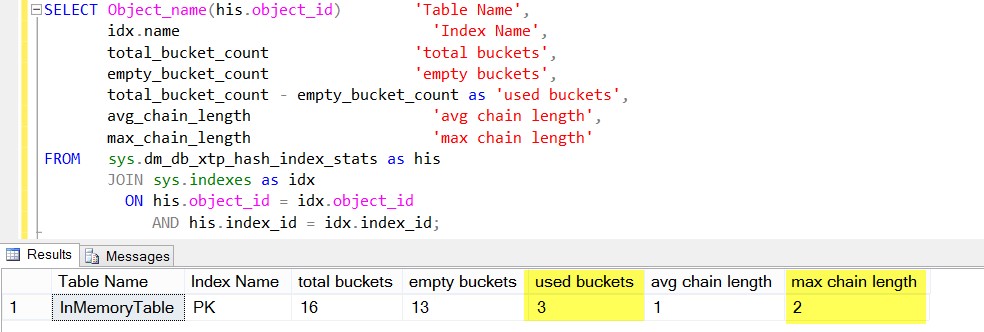
As you can see, we have only three buckets used and max chain is 2, which is for Microsoft and Collision.
One of the major questions asked by developers implementing SQL Server in-memory tables revolves around, where are these tables stored? How are entries written into them? How can we know more about their architecture? My recent blog post, SQL Server In-Memory tables – Where is Data Stored? answers those questions. If you’re concerned about how the data is stored, please read my other blog: SQL Server: In-Memory and Durable. How is That Possible?
For any further questions about SQL Server or the hash index, feel free to contact a Datavail DBA expert and we would be glad to help.
For further reference review this white paper by Microsoft.
