Amazon Aurora New Feature: Write Forwarding for Secondary AWS Regions
Author: Dilip Kumar | 4 min read | September 2, 2020
Gone are the days of DBAs having to use secondary cluster for disaster activity. Amazon Aurora has a new feature available for write forwarding that can help using your secondary clusters. Aurora write forwarding can help address some of the current challenges and limitations with Aurora Multi-Master.
The new write forwarding feature means less stress to your master server in terms of the connection going to a single endpoint. This also means you can now use SQLs to connect from secondary endpoint to your primary master endpoint (as writes) from your application end.
By using this approach, you can send all your transactions to secondary which will then apply on the primary server and then replicates back to your replicas. Please remember you should have Aurora 2.08.1 as the latest version to implement these features in your instance and the default isolation setup to work. As of now REPEATABLE READ & READ COMMITTED isolation works much better than other isolation setup.
Please follow these steps to enable auto-forwarding
Assuming you have an Aurora 2.08.1 with single writer as of now and you will be adding a new region secondary cluster toward the cluster.
Step 1: In your existing cluster add a new region by using this method shown below:
Existing setup with one cluster, primary + writer in Aurora 2.08.1

Step 2: Add secondary cluster by selecting via “Add region” to your cluster from Global given below.
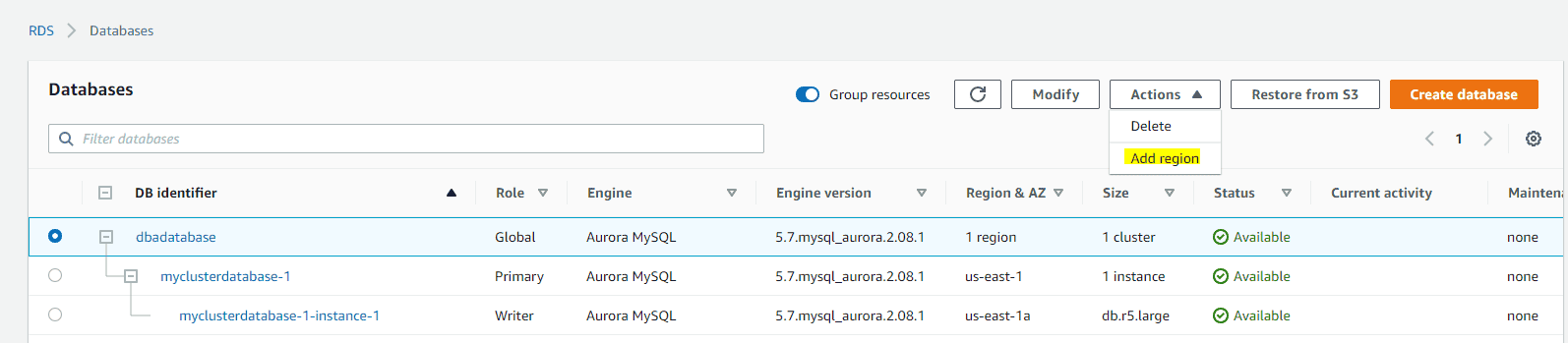
Choose your region:
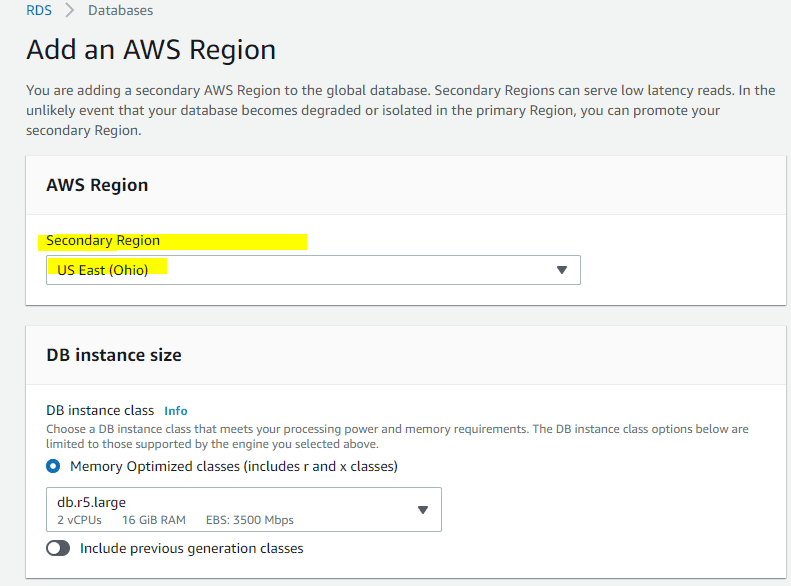
Make sure Read replica write forwarding is enabled while creating new secondary cluster towards new region given below.
Choose Availability & durability:
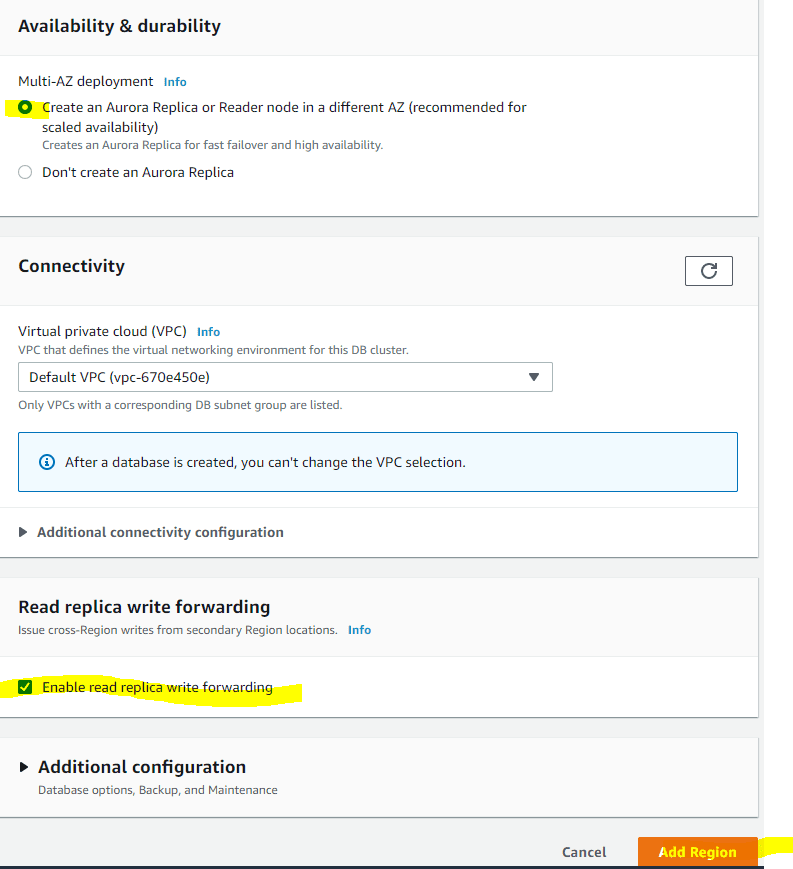
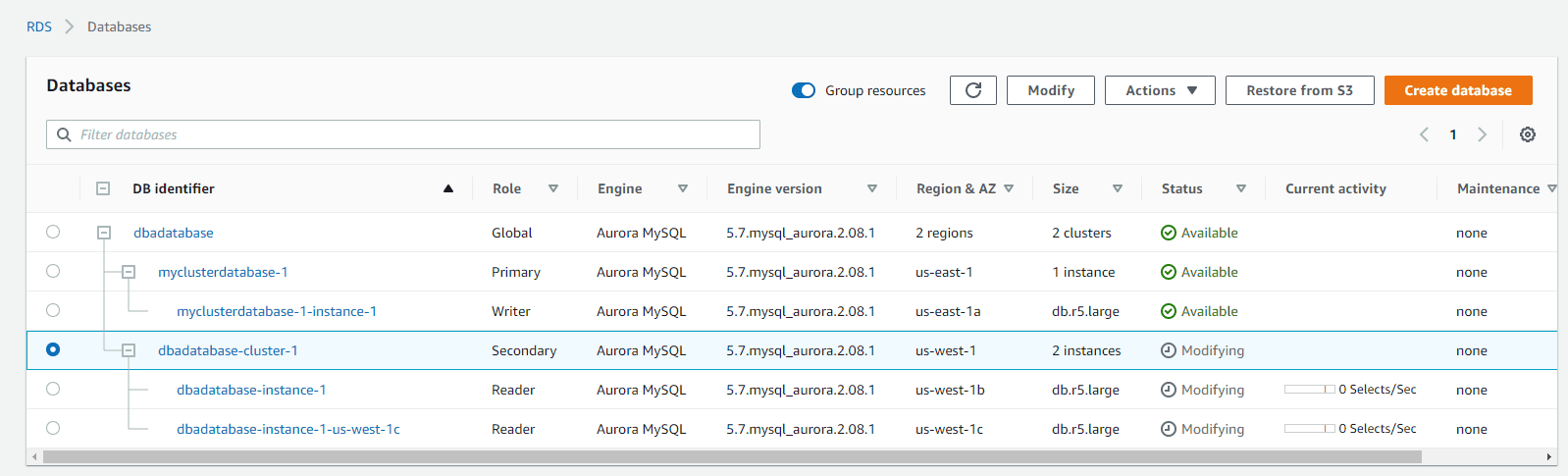
After clicking Add Region, this will create a new secondary cluster toward your global cluster along with Read replica (Reader) in that new region and it will look like the below. You’ll have two (2) replica in this region created.
Create status of your cluster:

Once the secondary cluster in your region is ready with reader you will see something like this the creating stage:

You will need to disable “read_only” parameter in your parameter file only on the secondary cluster used, so it can be used to read and write operations. Edit the cluster parameter file and disable the read_only parameter by having the copy of the existing default file. Then, apply to it using modifying the instance to your secondary cluster, shown below and readily available.
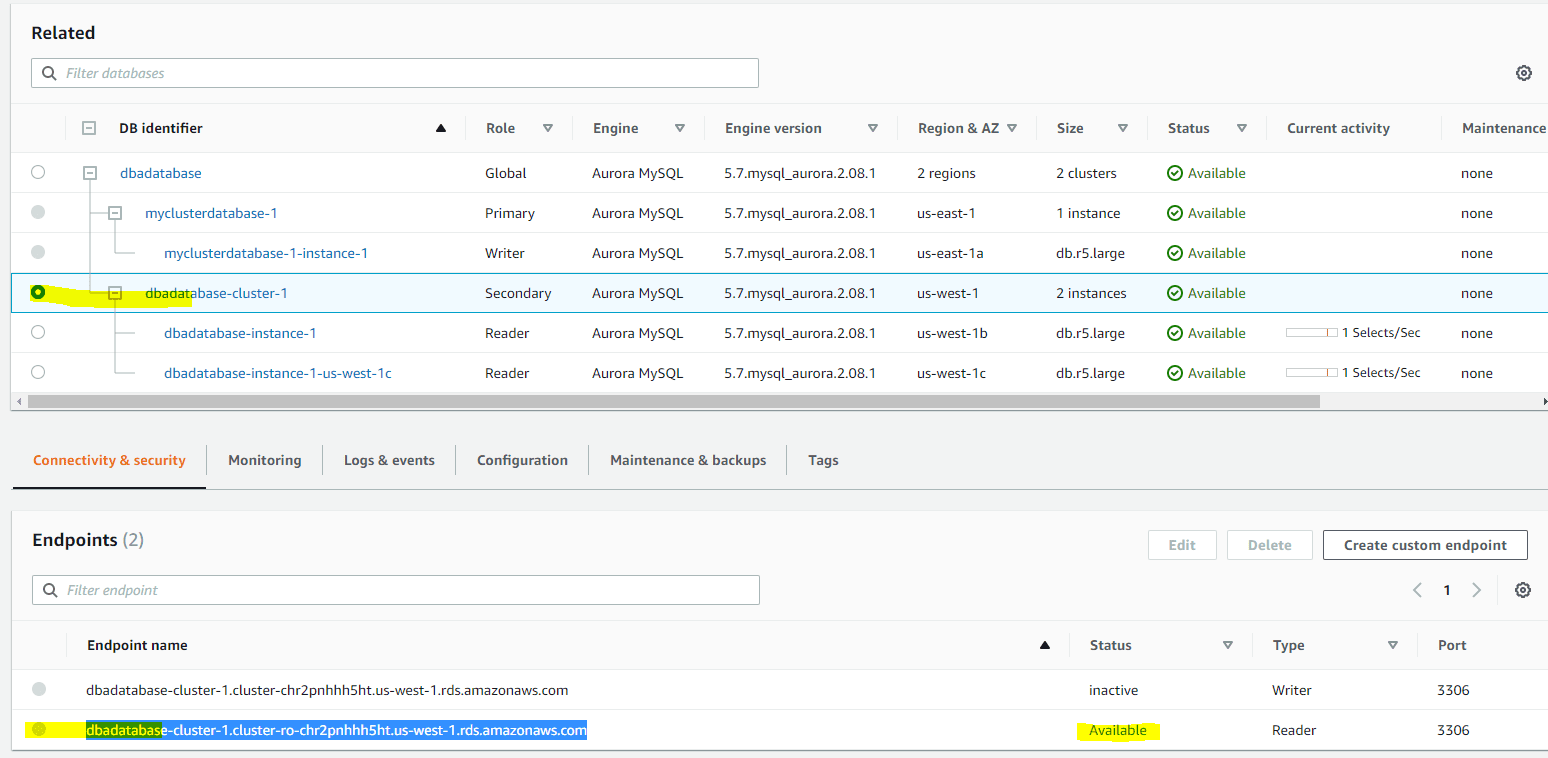
Click on the secondary cluster instance to see the endpoint names shown above.
Now open the terminal or putty or using external tools connected to the primary instance, create database and create table like the below from primary:
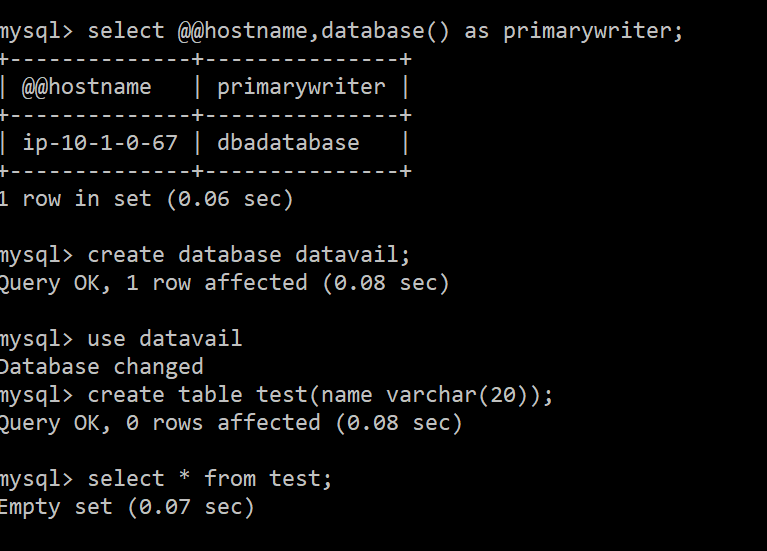
Now login into the secondary cluster which has Reader added to it at the time of the creation, use that endpoint to connect to the secondary instance and do the DML operations, you’ll have two databases used to insert some values towards the table:
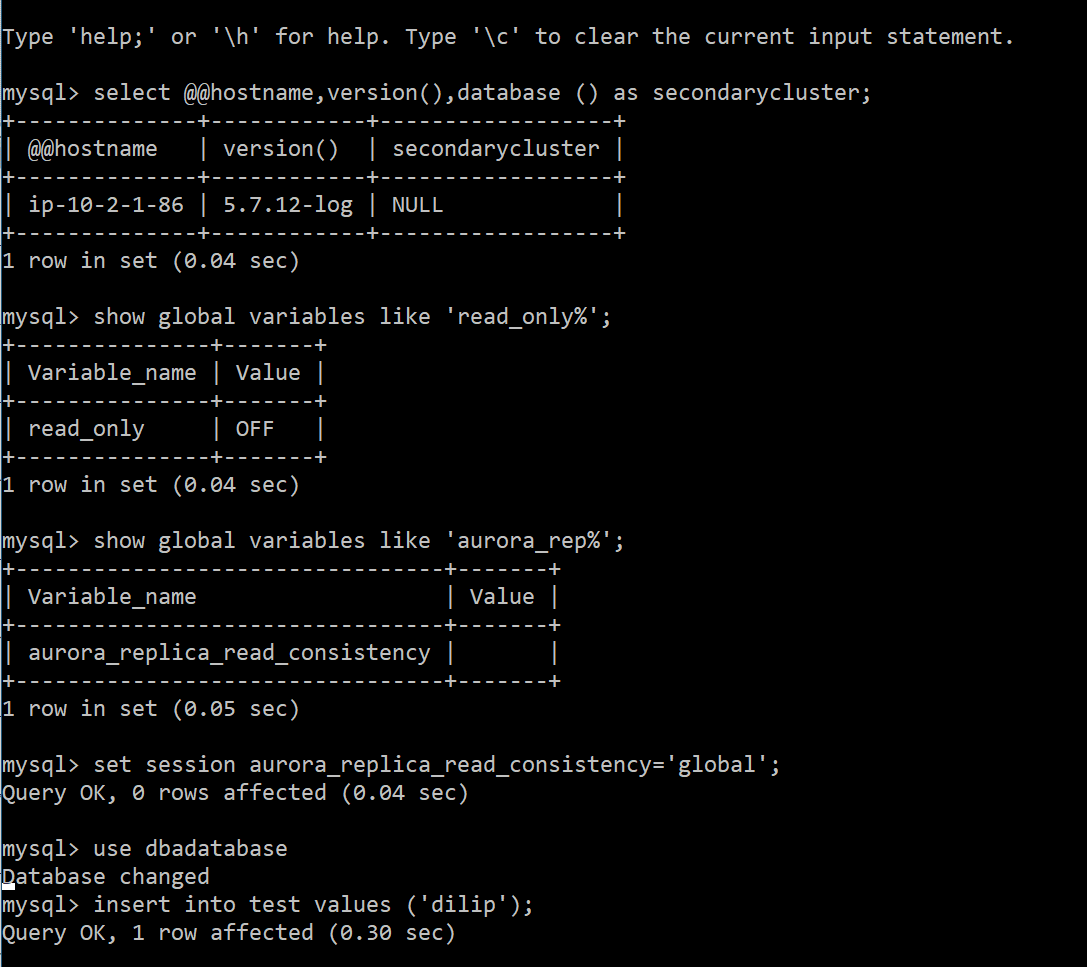
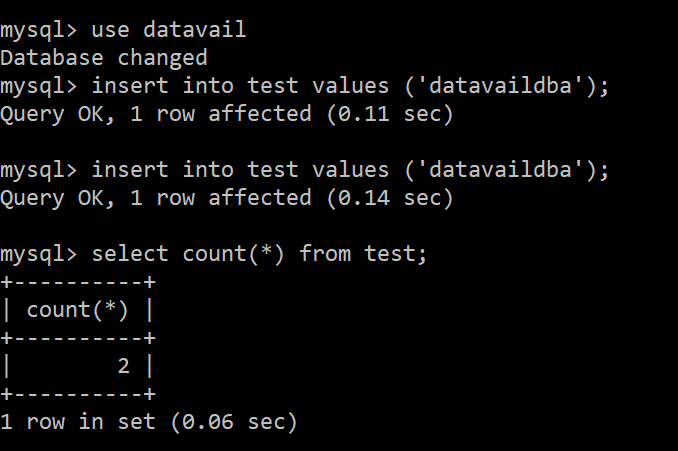
If you disable aurora_replica_consistency variable to NULL, your secondary cluster will not work for writes (DML’s), so make sure your application uses the below statements via session to enable writes, this feature must be set. please find the snip below as an example shown:
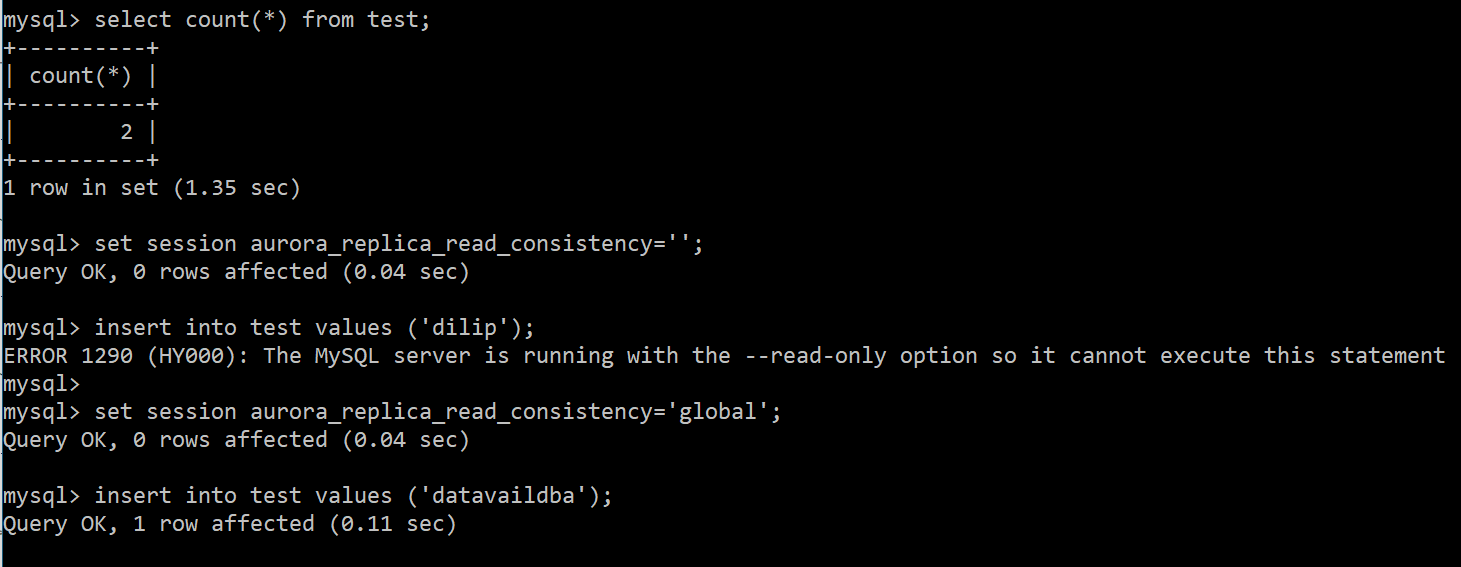
When you set the session variable to aurora_replica_read_consistency other than NULL, then only you can do the DML operations using your secondary cluster with assigned endpoint it has.
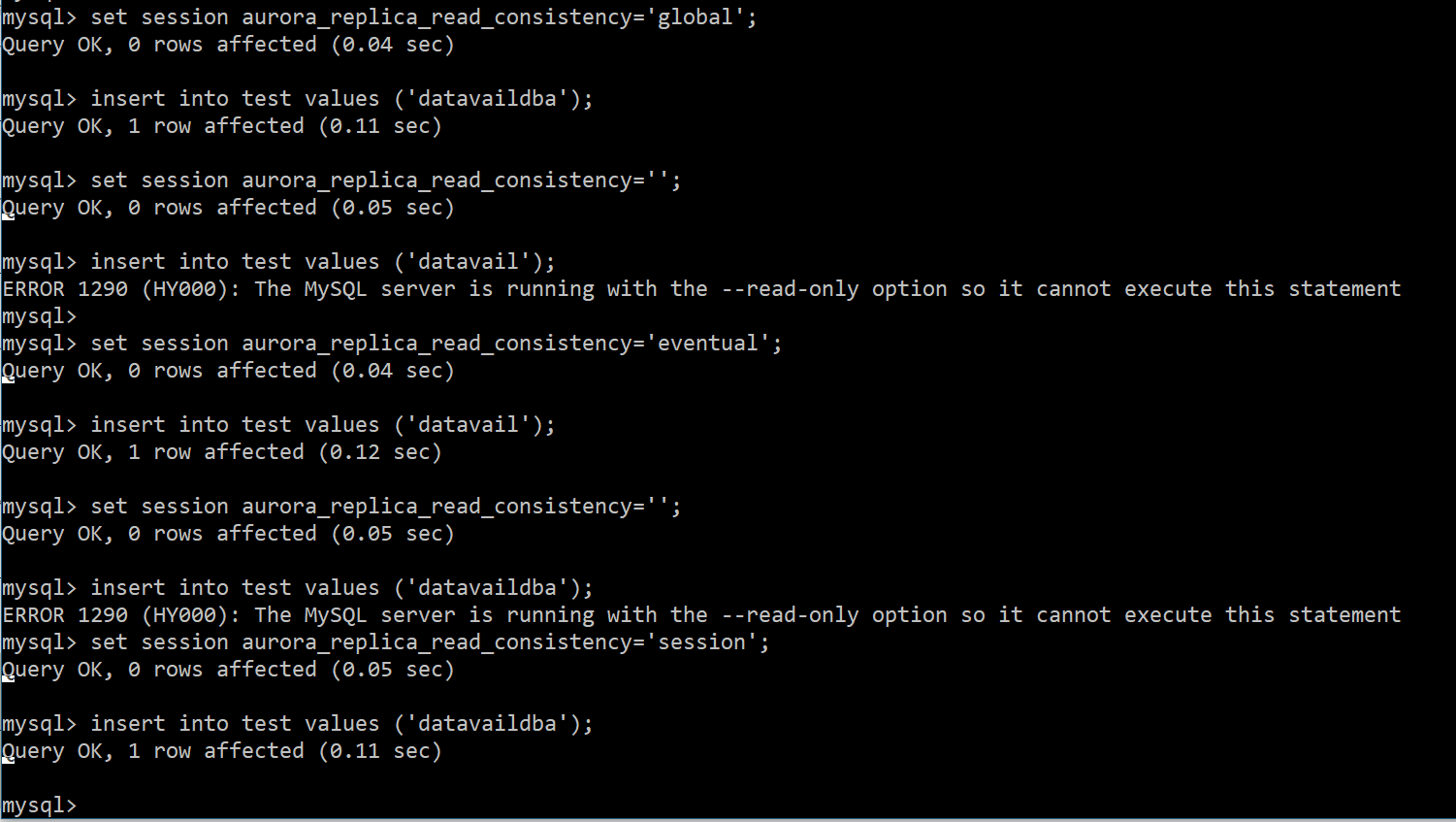
Note: Only DML can be done from secondary, once the session aurora_replica_read_consistency variables is set as global/session/eventual with any one of these. Please see the above snippet shows using three different types of levels used to write operations from secondary cluster.
In contrast, multiple inserts can be scaled using the existing endpoints within the cluster had; and the advantage of using is that the (primary & secondary) Aurora cluster is always in sync with each other. Though it’s accepting multiple DML’s due to the demand and the flexibility the “Write Forwarding” feature that Aurora has support for your application.
This post showed you how to use multiple DML’s from your application using the secondary cluster to replicate your data to primary and secondary in your environment. My hope is that you can now greatly improve writing of data to your tables for a very active database server. If your looking for support with write forwarding and/or your databases or are interested in an AWS migration, please reach out.
