Automating Replication Tear-downs and Rebuilds
Author: Andy McDermid | | April 6, 2017
SQL Server replication will not stand up to some kinds of DDL changes (e.g. drop). To support code deployments to replicated databases, it is typical to remove the replication before executing the code deploy project, and rebuild the replication afterwards. In general, the process looks like this:
- Script-out the replication
- Tear-down the replication
- Perform the code deploy project
- Rebuild the replication (script-in)
The replication steps on either end of the code-deploy require quite a bit of effort and time for even a simple code-deployment. These steps are also prone to error when done manually. Since the duration of the project affects the availability of the DSS systems (i.e. the subscriber databases) it is ideal to get it done quickly and correctly. It makes good sense to automate the replication tear-down and rebuild steps. This is a summarized case study on how to set up automated tear-downs and rebuilds for replication.
Identify the Articles
In general, the articles that make up a publication are predefined and static – i.e. after each project the replication is rebuilt just as it was before the project – so it is easy to define a list of the required articles. Once identified they can be added to a table (preferable in a dedicated administration database). We can call this table ‘article_master.’ At a minimum, the table will have these columns:
- ID – key for the table.
- Article – article name, AKA object name.
- ArticleType – the type of the article object. This can be ‘Table,’ ‘View,’ ‘Procedure,’ or ‘Function.’ These values are important as they will figure in the rebuild process.

Identify the Publication
Just like we set the details of each article down in a table, we can do the same for publication(s). We’ll call this table ‘publication_master:’
- ID – Key for the table.
- BuildDate – Date-time when the replication was built (or rebuilt.)
- PublisherInstance – SQL instance name of the publisher (e.g. SERVER01\SQLPROD).
- PublicationName – Name of the publication.
- DatabaseName – Name of the database containing the published articles.
- ArticleName – Name of the article. We’ll get this from the article_master table.
- SourceSchemaName – Schema name of the object sourcing the article.
- SourceObjectName – Name of the object sourcing the article.
- SourceType – Type of object. This comes from the ArticleType column in the article_master table. Each type gets translated to a type code used in the replication build call (e.g. a view maps to ‘view schema only’, a table maps to ‘logbased’).
- SubscriberInstance – SQL instance name of the subscriber (e.g. SERVER02\SQLREPORTS).
- InitializingBackup – Path to a file share to store backups for replication initialization.
The core of automating the replication rebuild is essentially archiving the script-out/script-in information (steps 1 and 4 above). In these two tables, we are documenting everything we need to build replication (and tear it down). The next step is to populate the publication_master table with the values we’ll use later to build TSQL statements to call replication scoped system stored procedures.
A ‘replication_master’ stored procedure
We can populate publication_master via a call to the ‘replication_master’ stored procedure. We’ll pass in the publisher instance and subscriber instance, among other parameters, for a given project, and the procedure will populate the table to look something like this:

Now we have all the info we need to tear down and rebuild replication for a project. The next step is to iterate through these rows, build the relevant TSQL strings to do the work, and set those TSQL strings up as job steps in the SQL Agent. While the first part of replication_master populates the tables, the latter half acts as a ‘wrapper’ to call stored procedures to create those SQL Agent Jobs.
A ‘tear-down’ stored procedure
The tear-down procedure has a few things to do to make sure replication is dropped cleanly and completely.
- sp_dropsubscription: Drop subscriptions for the database on the publisher — this also drops all articles.
- sp_droppullsubscription: Drop the pull subscription — this deletes the subscription on the subscriber side including the synch SQL Agent job.
- sp_droppublication: Drop the publication.
- sp_replicationdboption: Disable the database for publication.
- tsql script: To be certain replication is completely removed it may be necessary to remove any leftover replication jobs on the subscriber (the system procedures don’t do this reliably). Replication jobs names have a defined pattern so, using info from the publication_master, it is simple to create a script to drop any jobs matching these templates.
- log reader job: <publisher instance>-<publication name>-<publication database>-NNNN
- distribution job: < publisher instance>-<publication database>-<publication name>-<subscriber instance>-<subscriber database>-GUID
Let’s step through the tear-down stored procedure – we’ll skip ahead a bit right away and assume we have already queried the publication_master table and stored the relevant values in varchar variables (e.g. @PublicationName, @PublicationInstance, etc.). We have also programmatically added a “replication_tear-down” job and attached a schedule. The first step we want to add to the job is to drop the subscription with the sp_dropsubscription stored procedure. Based on the values in the table (set as varchars vars in the proc) we can concatenate a string like this:
SET @SQL = 'exec sp_dropsubscription @publication = '''+@PublicationName+''', @subscriber = '''+@SubscriptionInstance+''', @article = N''all'''
In this case, the system stored procedure (sp_dropsubscription) is run on the publisher side (@PublicationInstance), but other procedures will need to be run on the subscriber (and\or distributor) side(s), so we need a way to call this against any server name. Sqlcmd comes in handy here and we can build another string for that call.
set @SQLCMD = 'sqlcmd -E -S"'+@PublicationInstance+'" -d"'+@DBName+'" -Q"'+@SQL +'"'
Finally, we are ready to add this step to our tear-down job. Note the @command parameter is set to our SQLCMD string and the @subsystem is ‘CmdExe’ – i.e. to support sqlcmd this will be a command-line step within the job:
EXEC msdb.dbo.sp_add_jobstep @job_name=@teardownjobname, @step_name=@jobstepname, @step_id=@JobStepCounter, @cmdexec_success_code=0, @on_success_action=3, @on_success_step_id=0, @on_fail_action=2, @on_fail_step_id=0, @retry_attempts=0, @retry_interval=0, @os_run_priority=0, @subsystem=N'CmdExec', @command=@SQLCMD, @output_file_name=@pathtologfile, @flags=0
We follow suite with the other procedure calls and build a Cmd job step for each. The steps in the resulting job look like this:
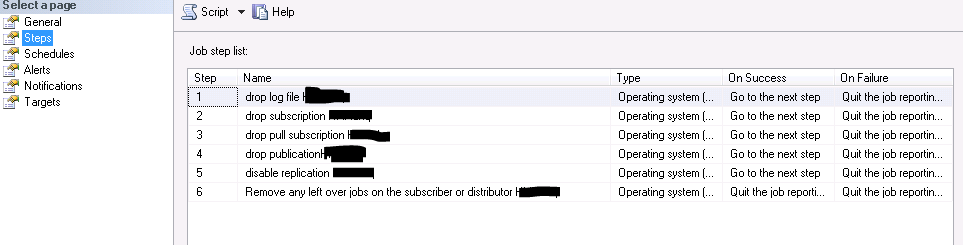
A ‘re-build’ stored procedure
Like the tear-down proc, the build proc will use the information documented in the publication_master table to create a job to build (rebuild) replication. It’s a bit more complicated since we need to add each article via a stored procedure call and each of those will be a job step. For a publication with many articles that can mean a lot of job steps! Also, since we initialize the replication via backups, we need steps to backup and restore the publishing database. Lastly, there may be any number of extra or custom steps to configure the replication for production. To build (rebuild) replication we need to:
- sp_replicationdboption: Enable the database for publication
- sp_addlogreader_agent:Add the log reader job
- sp_addpublication: Create the publication
- sp_addarticle: Add all the articles – to do this we must iterate though all articles in the publication_master table and add each as a job step
- backup the publication database to a shared location
- restore the database to the subscriber from a shared location
- sp_addsubscription: Initialize replication on the publisher
- sp_addpullsubscription: Add subscription on the subscriber (i.e. initialize the replication on the subscriber)
- sp_addpullsubscription_agent: Add the distribution job to the subscriber
Again, let’s start mid-procedure and assume we have already queried the publication_master table and set all the variables we need and have also programmatically added a “replication_build” job and attached a schedule. The first step we want to do is exec sp_replicationdboption to enable the database for publication. Building a string for that looks like this:
SET @SQL = 'exec sp_replicationdboption @dbname = N'''+@DBName+''', @optname = N''publish'', @value = N''true'''
Adding it to a SQLCMD call looks like this:
SET @SQLCMD = 'sqlcmd -E -S"'+@PublicationInstance+'" -d"'+@DBName+'" -Q"'+@SQL +'"'
And, finally, creating the job step looks like this:
EXEC msdb.dbo.sp_add_jobstep @job_name=@buildupjobname, @step_name=@jobstepname, @step_id=@JobStepCounter, @cmdexec_success_code=0, @on_success_action=3, @on_success_step_id=0, @on_fail_action=2, @on_fail_step_id=0, @retry_attempts=0, @retry_interval=0, @os_run_priority=0, @subsystem=N'CmdExec', @command=@SQLCMD, @output_file_name=@pathtologfile, @flags=2
This is the same process as generating the tear-down job steps, and similarly, it is repeated for each build requirement. However, as explained above, the build job differs from the tear-down job in that each article needs be added via a separate step. Here is a sample of the TSQL to create the string for each call to add an article:
SELECT @SQL = CASE WHEN SourceType ='logbased' THEN 'IF EXISTS (select * from sys.objects where name = N'''+@Article+''') exec sp_addarticle @publication = N'''+@DBName+''', @article = N'''+@Article+''', @source_owner = N''dbo'', @source_object = N'''+@Article+''', @type = N'''+@ArticleType+''', @identityrangemanagementoption = N''manual'',@status = 24,@ins_cmd = N''CALL [sp_MSins_'+@Article+']'',@del_cmd = N''CALL [sp_MSdel_'+@Article+']'', @upd_cmd = N''SCALL [sp_MSupd_'+@Article+']'' '
Note the case statement on SourceType. The sp_addarticle procedure takes this ‘logbased’ source type as an argument (the other types are included later in the case statement but,for brevity, are not shown here). That is why it is important to include the SourceType in the article_master table as mentioned earlier in this document. Also, note the ‘IF EXISTS’ test to ensure the object exists before trying to add an article based on that object.
The other big difference between tear-down and build jobs is, of course, the backup and restore steps to ‘synch’ the publication and subscriber databases before initializing the replication. It’s important to reduce the backup duration as much as possible so it’s worth looking into the buffercount and maxtransfersize arguments of the backup statement. Otherwise, the backup and restore steps are similar to the other steps; build a TSQL string, add it to a SQLCMD string, and add that to a job step.
SET @SQL = 'backup database '+@DBName+' to disk = '''+@InitializingBackup+''' with init, compression, buffercount=112, maxtransfersize = 4194304'4
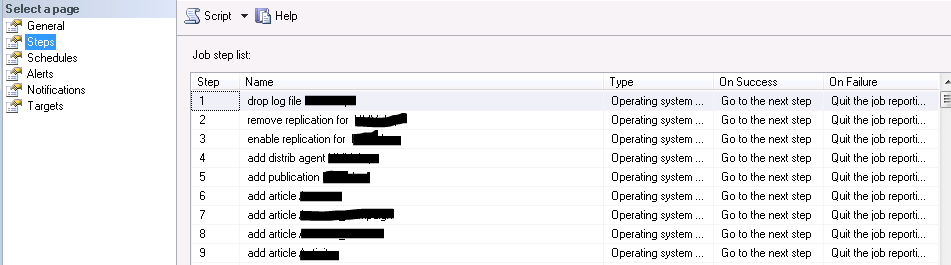
The completed build job has more than 350 steps (to include many articles) so I split-up this screen shot to show the first and last steps. Here you can see some of the steps mentioned above as well as the first few of many ‘add article’ steps:
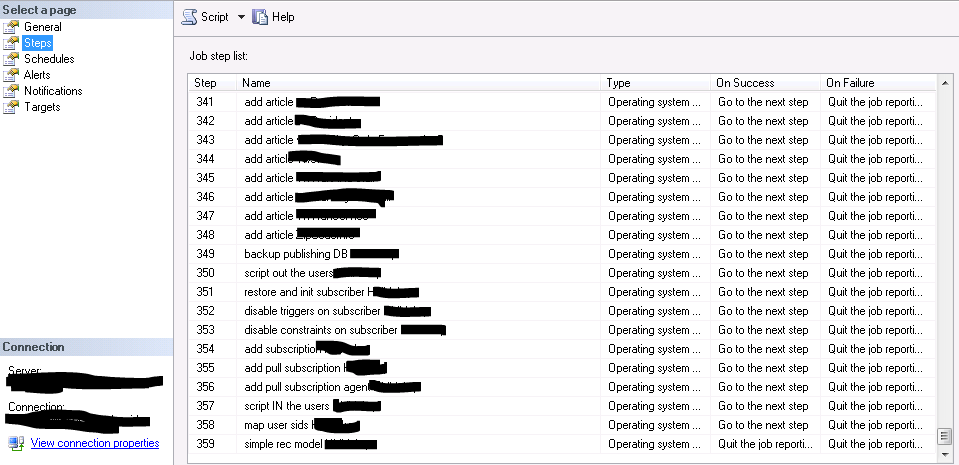
The last steps of the job wraps-up the ‘add article’ steps and follows with backup, restore, and replication initialization steps as described above as well as some other important optimization and customization steps for replication (these include script-out\script-in custom subscriber users, map SIDs, disable triggers and some constraints, and set the subscriber DB to SIMPLE).
Scale Up
To build both the tear-down and the rebuild jobs it only requires a single execution of replication_master stored procedure per publication. The walk-though in this document just considers a single publication for simplicity. But it is easy to scale up this bare-bones example so that tear-downs and rebuilds for a large project – for instance, a code deploy to many replicated databases – can be easily automated and scheduled to reduce effort and errors and minimize DDS system in-availability. It’s also fairly simple to build on this system to support custom articles for specific databases and for additional subscriber or distribution instances.
Please let me know if you have questions or comments, or if you’d like to learn more.
Happy tear-downs and builds (rebuilds)
Datavail Script: Terms & Conditions
By using this software script (“Script”), you are agreeing to the following terms and condition, as a legally enforceable contract, with Datavail Corporation (“Datavail”). If you do not agree with these terms, do not download or otherwise use the Script. You (which includes any entity whom you represent or for whom you use the Script) and Datavail agree as follows:
1. CONSIDERATION. As you are aware, you did not pay a fee to Datavail for the license to the Script. Consequently, your consideration for use of the Script is your agreement to these terms, including the various waivers, releases and limitations of your rights and Datavail’s liabilities, as setforth herein.
2. LICENSE. Subject to the terms herein, the Script is provided to you as a non-exclusive, revocable license to use internally and not to transfer, sub-license, copy, or create derivative works from the Script, not to use the Script in a service bureau and not to disclose the Script to any third parties. No title or other ownership of the Script (or intellectual property rights therein) is assigned to you.
3. USE AT YOUR OWN RISK; DISCLAIMER OF WARRANTIES. You agree that your use of the Script and any impacts on your software, databases, systems, networks or other property or services are solely and exclusively at your own risk. Datavail does not make any warranties, and hereby expressly disclaims any and all warranties, implied or express, including without limitation, the following: (1) performance of or results from the Script, (2) compatibility with any other software or hardware, (3) non-infringement or violation of third party’s intellectual property or other property rights, (4) fitness for a particular purpose, or (5) merchantability.
4. LIMITATION ON LIABILITY; RELEASE. DATAVAIL SHALL HAVE NO, AND YOU WAIVE ANY, LIABILITY OR DAMAGES UNDER THIS AGREEMENT.
You hereby release Datavail from any claims, causes of action, losses, damages, costs and expenses resulting from your downloading or other use of the Script.
5. AGREEMENT. These terms and conditions constitute your complete and exclusive legal agreement between you and Datavail.

Blog Author
Related Posts

How to Solve the Oracle Error ORA-12154: TNS:could not resolve the connect identifier specified
The “ORA-12154: TNS Oracle error message is very common for database administrators. Learn how to diagnose & resolve this common issue here today.

Data Types: The Importance of Choosing the Correct Data Type
Most DBAs have struggled with the pros and cons of choosing one data type over another. This blog post discusses different situations.

How to Recover a Table from an Oracle 12c RMAN Backup
Our database experts explain how to recover and restore a table from an Oracle 12c RMAN Backup with this step-by-step blog. Read more.