Accelerated Database Recovery Alleviates DBAs’ Frustrations
Author: Santosh Bhosale | | August 20, 2020
Many DBAs, such as myself have gotten frustrated at some point or another by long-running transactions with improperly written queries that are filling up databases transaction logs, causing SQL dumps, etc. Then, it gets worse when such transaction gets aborted ending up into never-ending rollback recoveries. Accelerated Database Recovery feature is an enhanced recovery process that can help us all avoid such problems.
Accelerated Database Recovery (ADR) is a new feature that comes with SQL 2019 and Azure SQL database, it helps speed up the database recovery process and decreases rollback time for any long running large transactions when aborted. ADR feature is also available on Azure database and some of its major benefits include quicker and reliable recovery, quicker rollback. Plus, it doesn’t matter how much a longer running transaction you have or how many active processes you have on server, it keeps truncating log file to keep its growth under control.
The ADR Process
Let’s looks at the different elements of ADR. It comes with mainly three new structures: PVS, ATM, and S-Log and fourth one is Cleaner; these new components helps ADR more efficiently and quickly.
- Persistent Version Store (PVS) – this mechanism stores row versions within the database and not on tempdb. You can create a different file group on database and place PVS on it. It stores changes on every row, earlier versions of that row and if needed, a pointer to the earlier version in the version store can be saved too.
- Logical Revert – this component is responsible to perform row-level version-based undo as per the data stored on PVS to rollback any process in case of rollback command or in case of system crash.
- S-Log – “Secondary logs” are in-memory logs; SQL use them to store processes that cannot be versioned; like getting locks for DDL or bulk commands. If a database has ADR enabled on it, corresponding S-Log gets reconstructed in analysis stage of recovery and it gets used in redo phase instead of trn logs; as Slogs stored in-memory it speeds up the recovery. Slog also stores minimal data e.g. info about exclusive locks etc. It is also used during the undo stage.
And then last component which is Cleaner:
- Cleaner – this process run periodically and cleans up unwanted page versions. You can also run sp_persistent_version_cleanup and manually initiate cleanup process
Now let’s see how traditional recovery works vs ADR recovery process and what’s makes ADR faster and more efficient.
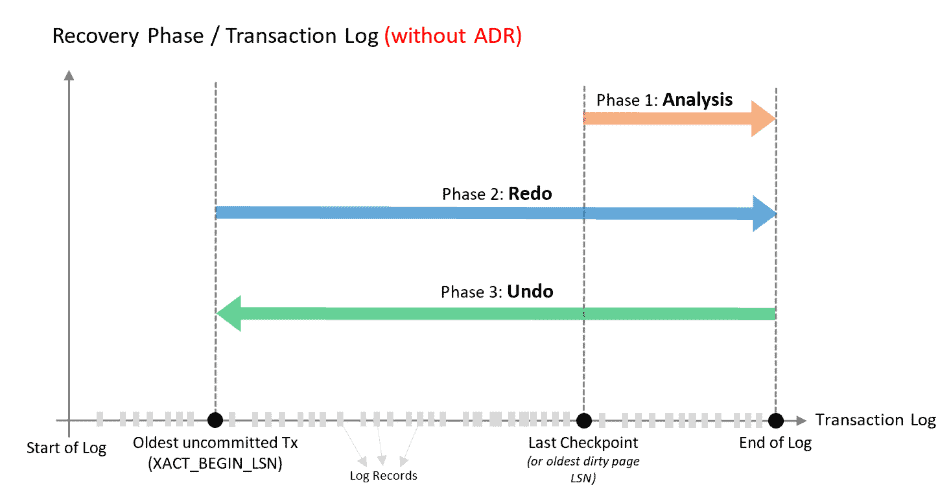
Below image illustrates a traditional Database recovery process; (Ref. – MS Documents)
-vs-
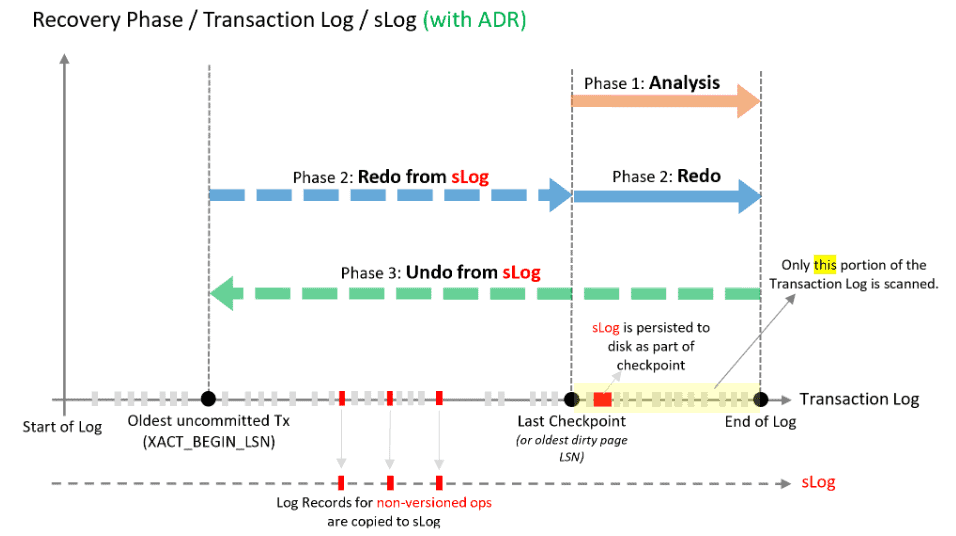
Below image depicts the ADR process; (Ref. – MS Documents)
This recovery process consists of three steps:
- Traditional Analysis Stage – brings all the transactions to the same state at the time of SQL Server crash\stop, it must read transaction log from last checkpoint and scan it in forward direction till the end of log.
-vs-
ADR Analysis Stage – it follows same steps as of traditional analysis stage; but it also creates Slog and stores non-versioned operation logs on it.
- Traditional Redo Stage – in this stage SQL scans transaction log into forward direction from oldest uncommitted transaction to the end of the log and bring all the transactions into the state where they were at the time of system crash.
-vs-
ADR Redo Stage – it is a 2-part stage, in the first part, SQL scans S-log into forward direction from oldest uncommitted transaction to the end of the S-log. It is a quicker operation as S-logs holds fewer records (it only holds non-versioned operation logs). In the second part, it reapplies all the Trn logs from last checkpoint.
- Traditional Undo Stage – like the name suggests, SQL goes into reading logs in the reverse direction and rolls back all changes made by the transaction active at the time of system crash.
-vs-
ADR Undo Stage – to rollback active transactions at the time of system crash, it uses S-log and PVS which stores non-versioned and row level versions of each transactions respectively. Hence it is a much quicker process. It uses the same Undo mechanism when someone cancels long running transactions as well.
With this comparison, it’s clear that with traditional recovery the time for recovering databases is greater because it depends on the size of active transaction when the server crashed or rolling back transactions. Where with ADR, it’s not the case; it uses PVS and S-log to speed up recovery. It also controls growth of Trn logs; by truncating logs in regular intervals; ADR need not have to wait until long transaction finishes to truncate log.
Microsoft specifically recommends ADR for databases having very long-running transactions, extreme transaction log growth, or if you have databases with high recovery time when SQL Server unexpectedly restarted or someone manually initiate rollback for any long transaction.
It is a nice feature that comes with SQL 2019, but it also slows down all DML operations due to versioning operations it needs to perform. That’s the reason, by default this database option is turned off and you can enable it by carefully evaluating your environment and needs. If your looking with ADR or SQL Server support, please reach out to our experts.

Blog Author
Related Posts

How to Solve the Oracle Error ORA-12154: TNS:could not resolve the connect identifier specified
The “ORA-12154: TNS Oracle error message is very common for database administrators. Learn how to diagnose & resolve this common issue here today.

Data Types: The Importance of Choosing the Correct Data Type
Most DBAs have struggled with the pros and cons of choosing one data type over another. This blog post discusses different situations.

How to Recover a Table from an Oracle 12c RMAN Backup
Our database experts explain how to recover and restore a table from an Oracle 12c RMAN Backup with this step-by-step blog. Read more.